
1. Innledning
Metrikken springer ut av språket. At språk er rytme, er tydelig helt fra den tidlige rytmiske interaksjonen mellom mor og barn til de utviklede setningenes jevne tidsintervaller – trykkbasert i noen språk, som norsk, stavelsesbasert i andre språk, som fransk, lengdebasert i atter andre.
Men er språk også rim? Er versenes rim også en regularisering av noe vi allerede finner i språket?
Bokstavrim eller allitterasjon er en klassisk rimtype karakteristisk blant annet for norrøn og annen gammelgermansk poesi, der allitterasjonen fulgte faste og strenge mønstre. Et eksempel er en ljodahått-strofe funnet som runeinnskrift på Bryggen i Bergen. I ljodahått skal en trykkstavelse i første linje stavrime med første trykkstavelse i annen linje, og så skal det være stavrim mellom to trykkstavelser i tredje linje:
Sæl(l) ek þá þóttumk,
er vit sátumsk i hjá,
ok komat okkar maðr á meðal.
‘Jeg syntes meg sæl
da vi satt sammen
og ikke et menneske kom mellom oss.’
Det blir ofte påpekt at ordtak og faste vendinger i moderne norsk og andre språk har en tilbøyelighet til å allitterere. Hvor sterk er denne tilbøyeligheten – kan det tallfestes? Hvor mye oftere forekommer allitterasjon enn man skulle vente hvis det ikke fantes noen tilbøyelighet til å velge allittererende ordsekvenser?
I dette innlegget skal vi begrense oss til å se på koordinering av to enkle substantiver (uten adjektiver eller andre tillegg). Innenfor denne konstruksjonstypen finnes det en god del faste vendinger: sans og samling, vær og vind, kunst og kultur, ny og ne, mål og mening, munn og mæle, hud og hår, liv og lære, hui og hast, skuffer og skap, vitende og vilje, osv. Men ikke alle slike faste vendinger allittererer: sett og vis, saker og ting, fred og ro, liv og helse, kjøtt og blod, tid og rom, osv.
Hvis vi vil undersøke hvor ofte allitterasjon opptrer i slike uttrykk, blir det et problem å avgrense såkalte «faste uttrykk» fra koordinasjoner mellom to enkle substantiver i sin alminnelighet, på en tilstrekkelig presis måte til at statistikk blir informativ. Uavhengig av dette problemet kan det også være av interesse å undersøke tilbøyeligheten til å allitterere i uttrykk som ikke tilhører denne gruppen av faste vendinger. Man kan tenke seg i hvert fall to grunner til en eventuell tendens til allitterasjon. For det første kan det være at allitterasjon i faste uttrykk er noe av det som har bidradd nettopp til at de har festet seg og blir husket og gjentatt. For det annet kan man tenke seg at vi som språkbrukere har en tendens til å allitterere når anledningen byr seg. Hvis det siste er tilfellet, venter vi å finne en overvekt av allitterasjon også i koordinasjoner som ikke har etablert seg som faste uttrykk. Vi skal derfor se på hele mengden av koordinasjoner av nevnte type i vårt korpus NorGramBank.
2. Avgrensning og søk
(a) Koordinasjoner med allitterasjon
Vi skal søke etter koordinerte substantiver med ulike konjunksjoner (og, eller osv.) der ingen av substantivene har tilknyttede bestemmere, adjektiver eller andre fraser. Det utelukker f.eks. eksempler som mindre forurensning og mindre kø, lokalsamfunnet og de regionene de betjener, osv., og inkluderer bare eksempler av den typen som er nevnt i innledningen (med og uten allitterasjon). Dette betyr koordinasjoner med c-struktur (trestruktur) som i Figur 1, der NP-nodene ikke forgrener seg. (NP = nominalfrase.)
Figur 1: Frasestrukturen i en enkel koordinasjon av substantiver
Vi begrenser oss videre til koordinasjoner der begge substantivene begynner på konsonant – ikke fordi alliterasjon med vokaler er irrelevant, men fordi den har litt andre regler enn konsonant-allitterasjon, ettersom det først og fremst er ulike vokaler som allittererer (åker og eng), og vi behøver ikke å ta høyde for den komplikasjonen for å studere tallforholdene mellom allitterasjon og manglende allitterasjon. Vi begrenser oss da til følgende 15 konsonanter:
b d f g h j k l m n p r s t v
Vi søker i hele trebanken NorGrambank (ca. 70 mill ord); delene den består av (aviser, sakprosa, skjønnlitteratur, stortingsforhandlinger, drøyt ti prosent nynorsk), beskrives på denne siden. Søkeuttrykket som plukker ut allittererende tilfeller med strukturen i Figur 1, beskrives nærmere på siden Søk etter allittererende koordinasjoner. Dette søkeuttrykket finner koordinasjoner der de to substantivene har samme initiale konsonant i skrift. Dette kommer til å omfatte en del eksempler der de likevel ikke allittererer, først og fremst ved substantiver på gj- og hj-, som ikke allittererer med andre substantiver på g- eller h-, men med substantiver på j-, og tilsvarende ved substantiver på hv- og v-. Resultatet av søket er bearbeidet for å ta hensyn til dette. Vi står da igjen med ca. 11 960 forekomster av til sammen ca. 8 020 ulike koordinasjoner der substantivene allittererer. Vi tar utgangspunkt i formene i teksten og skiller mellom f.eks. bil og buss og biler og busser som ulike koordinasjoner. Tabell 1 viser de 8 020 ulike allittererende koordinasjonene sortert etter frekvens, med de hyppigste øverst.
Tabell 1:
Tabell over 8020 allittererende substantiv-koordinasjoner sortert etter frekvens
Innslaget av faste uttrykk er klart sterkere jo høyere frekvenser vi betrakter. Blant de 30 mest frekvente eksemplene finner vi de 19 faste uttrykkene rekke og rad, sans og samling, vær og vind, kunst og kultur, ny og ne, mål og mening, munn og mæle, penn og papir, hud og hår, liv og lære, hui og hast, skuffer og skap, vitende og vilje, fred og forsoning, fyr og flamme, himmel og hav, punkt og prikke, tang og tare, stokk og stein, med frekvenser mellom 139 og 24. Tabellen har en lang hale på hele ca. 6 860 eksempler med frekvens 1, og der er det langt mellom faste uttrykk. Men en nøyaktig grenseoppgang mellom faste uttrykk og vanlige produktive koordinasjoner er en vanskelig oppgave; frekvens i et finitt korpus kan ikke være det eneste kriteriet. Vi skal derfor ikke forsøke en slik grenseoppgang.
(b) Koordinasjoner med og uten allitterasjon
For å finne ut om allittererende eksempler er særlig hyppige, må vi sammenligne tallene for slike koordinasjoner med tallene for koordinasjon av to substantiver i sin alminnelighet, uavhengig av allitterasjon. Søkeuttrykket som finner alle slike koordinasjoner, er presentert i avsnittet 2. Alle koordinasjoner på siden Søk etter allittererende koordinasjoner. Søket finner ca. 87 820 forekomster fordelt over ca. 59 450 ulike eksempler. Tabell 2 viser de 3 418 mest frekvente av disse eksemplene, ned til og med frekvens 3:
Tabell 2:
tabell over de 3418 mest frekvente av alle 59450 koordinasjoner (med eller uten allitterasjon) av to substantiver
Vi ser at koordinasjoner som mor og far, mamma og pappa, kvinner og menn, sett og vis, menn og kvinner og liv og død, med mellom 591 og 195 forekomster, forekommer oftere enn de mest frekvente allittererende koordinasjonene (der den hyppigste, rekke og rad, forekommer 139 ganger). For å vurdere om det finnes en tendens til å velge allittererende koordinasjoner, må vi se på de globale tallene.
3. Er allitterasjon hyppigere enn vi skulle vente?
Hvis null-hypotesen er at allitterasjon ikke spiller noen rolle for valg av ord i en koordinasjon, venter vi at hver initialkonsonant i første konjunkt opptrer med seg selv som partner i annet konjunkt gjennomsnittlig like ofte som den opptrer sammen med hver av de øvrige 14 konsonantene. (Siden alle konsonantene er involvert som andrekonsonanter her, spiller ulik global frekvens av de enkelte konsonantene ingen rolle. At j- er generelt sjelden og derfor stiller svakt i konkurransen med de andre konsonantene som andrekonsonant etter j-, oppveies av at f.eks. s- er spesielt hyppig og derfor stiller sterkt i konkurransen etter en initial s-, osv.). Nullhypotesens forventning, basert på det totale antall koordinasjonsforekomster 87 820, er da at hver av de 15 konsonantene opptrer med seg selv som partner (87 820 : 15) : 15 = 390 ganger, som da er gjennomsnittet. Det faktiske antallet koordinasjonsforekomster med alliterasjon er, som vi så ovenfor, ca. 11 960. Det betyr at hver av de 15 konsonantene gjennomsnittlig faktisk opptrer med seg selv som partner 11 960 : 15 = 797 ganger, altså over dobbelt så ofte som nullhypotesens forventning, med en faktor på 797 : 390 = 2,04.
Dette bekrefter en tydelig overvekt av allittererende koordinasjoner. Men skyldes dette en levende tendens til å allitterere, eller bare at mange nedarvede faste uttrykk faktisk allittererer og derfor bringer tallene opp fordi faste uttrykk er spesielt hyppige? En måte å kontrollere dette delvis på, er å se bort fra frekvens ved den enkelte koordinasjonen og bare telle ulike koordinasjoner, altså typer. Av koordinasjoner generelt, med eller uten allitterasjon, finner vi som nevnt ca. 59 450 ulike. Med samme nullhypotese som ovenfor venter vi at hver av de 15 konsonantene opptrer med seg selv som partner i (59 450 : 15) : 15 = 264 ganger. Av allittererende koordinasjoner har vi ca. 8 020 ulike. Det betyr at hver konsonant opptrer med seg selv som partner gjennomsnittlig 8 020 : 15 = 535 ganger, igjen over dobbelt så ofte som gjennomsnittsforventningen, med en faktor på 535 : 264 = 2,03.
En annen måte å redusere innflytelsen fra faste uttrykk på, er å bare sammenligne koordinasjoner som har frekvens 1, altså forekommer bare én gang hver. Kandidater til ‘faste uttrykk’ er sjeldnere jo lavere frekvens vi står overfor. Vi finner ca. 51 280 koordinasjoner med frekvens 1. Av disse er ca. 6 860 allittererende. Med samme utregning som ovenfor er den gjennomsnittsbaserte forventningen at hver konsonant opptrer med seg selv som partner (51 280 : 15) : 15 = 228 ganger, mens de faktisk gjør det gjennomsnittlig 6 860 : 15 = 457 ganger, denne gang overvekt med en faktor på 457 : 228 = 2. Dette gjør det ikke urimelig å opprettholde hypotesen om en generell tendens til allitterasjon (og dermed forkaste nullhypotesen om bare gjennomsnittlig frekvens).
4. Fordelingen mellom konsonantene
(a) Eksemplarer (forekomster)
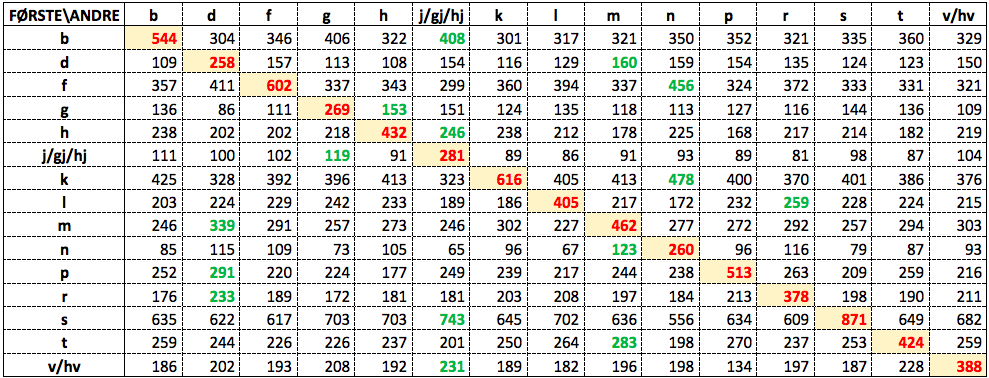
Distribueres preferansen for allitterasjon jevnt blant de 15 konsonantene, eller skiller noen seg ut som særlig bokstavrimglade? Antallene forekomster av de ulike parene av første og annen initialkonsonant fremgår av Tabell 3:
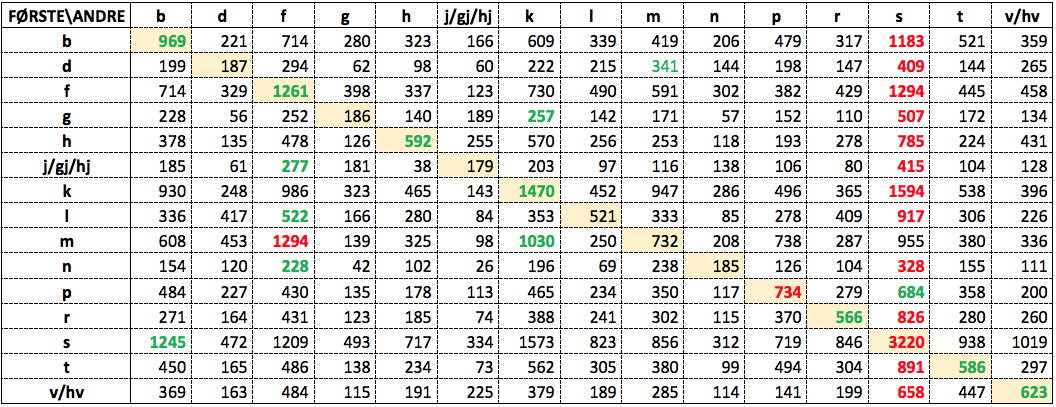 Tabell 3: Eksemplarfrekvenser av hver kombinasjon av første og annen initialkonsonant
Tabell 3: Eksemplarfrekvenser av hver kombinasjon av første og annen initialkonsonant
(Tabellen kan sees i større format her.)
Den loddrette aksen viser de 15 konsonantene som initialkonsonant i første konjunkt, og den vannrette aksen de samme konsonantene som initialkonsonant i andre konjunkt. Ved.v/hv og j/gj/hj er likelydende initialer slått sammen. Tallene viser frekvensene av tekstforekomster for hvert par av første og andre initialkonsonant. En overvekt av alliterasjon skulle da gi høye tall i diagonalen (markert med gult) fra øverst til venstre til nederst til høyre, altså parene b-b, d-d, f-f, g-g osv. Denne tendensen kamufleres likevel noe av ulikhetene i global frekvens mellom de 15 konsonantene, der f.eks. s globalt er flere ganger så frekvent som j/gj/hj eller n som initialkonsonant. Dermed blir koordinasjoner med s som annen initialkonsonant nesten alltid mer frekvente enn med hver av de øvrige andrekonsonantene, uansett andre tendenser. I hver linje i tabellen, altså for hver førstekonsonant, er den mest frekvente andrekonsonanten markert med rødt, og den nest mest frekvente med grønt. Vi ser at s dominerer fullstendig som den mest frekvente andrekonsonanten. Et unntak er paret m-f, der særlig koordinasjonen mor og far har mye av ansvaret, slik det fremgår av Tabell 2 ovenfor. Men hvis vi ser på de grønne nest høyeste tallene, finner vi 7 av de 15 i den omtalte diagonalen, der vi i tillegg finner to røde, ett for p-p, og selvsagt ett for s-s. En tendens til allitterasjon skinner altså igjennom frekvensdominansen av s og andre konsonanter.
Vi kan eliminere virkningen av ulikhetene i global frekvens mellom konsonantene ved å normalisere frekvenstallene i tabellen til det de ville ha vært hvis alle konsonanter hadde hatt samme globale frekvens. Vi regner da ut den gjennomsnittlige summen g av hver av de 15 kolonnene i tabellen: g = 5 853. Så finner vi det normaliserte frekvenstallet f-norm i hver celle ved å multiplisere det faktiske frekvenstallet f med resultatet av å dividere gjennomsnittssummen g med den faktiske kolonnesummen s, altså:
f-norm = f * (g/s)
Resultatet er Tabell 4, der hver kolonne har tilnærmet samme sum, omtrent lik gjennomsnittssummen g (‘omtrent’ fordi vi eliminerer desimaler).
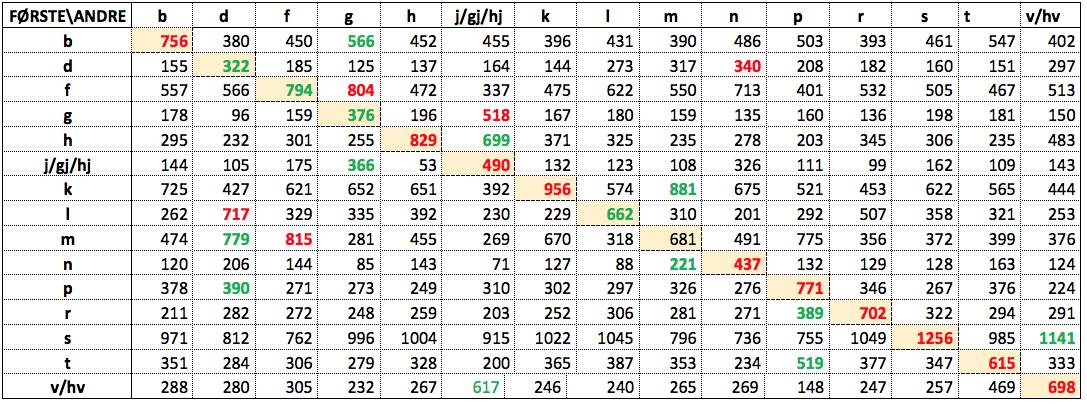 Tabell 4: Normaliserte eksemplarfrekvenstall basert på antatt lik frekvens mellom konsonantene
Tabell 4: Normaliserte eksemplarfrekvenstall basert på antatt lik frekvens mellom konsonantene
(Tabellen kan sees i større format her.)
I Tabell 4 fremtrer en rimelig tydelig rød allitterasjonsdiagonal, med grønne innslag. Et unntak fra rød diagonal er d-n, som vinner over d-d på grunn av koordinasjonene dag og natt, dagene og nettene, osv.; de er ansvarlige for over halvparten av treffene. Men den grønne andreplassen inntas av d-d. I neste linje vinner f-g over f-f, særlig på grunn av frukt og grønt, men også frukt og grønnsaker, fryd og gammen og flasker og glass. (Det lyder forøvrig som en hyggelig og sunn fest.) Men også her inntar den allittererende f-f en grønn andreplass. Når g-g i følgende linje må se seg slått av g-j/gj/hj, ligger skylden hos gutten og jenta, guttene og jentene osv. Den allittererende g-g er en grønn nummer to også her. Det samme er tilfellet ved l-l, der vinneren l-d kan takke liv og død for seieren, mens l-l kommer på andreplass. Den eneste førstekonsonanten som hverken har rødt eller grønt tall i diagonalen, er m, og her kan vi legge skylden på mor og far, og dernest på mat og drikke, mennesker og dyr og mor og datter.
I sum har vi 10 førsteplasser og 4 andreplasser av til sammen 15 mulige i den allittererende diagonalen (når vi altså normaliserer oss bort fra bokstavenes ulike globale frekvenser), og kan konkludere med at tendensen til allitterasjon er påtagelig på tvers av alfabetet, når vi teller teksteksemplarer.
(b) Typer
Det er høy tekstfrekvens som gjennomgående synes å være årsaken til avvikene fra allittererende vinnere i tabellene 3 og 4, og det kan derfor være interessant å se hvordan tabellene ser ut hvis vi teller bare ulike koordinasjoner (typer), og ikke teksteksemplarer, også for de enkelte konsonantene. Antallet ulike koordinasjoner, altså typer, for hvert par av initiale konsonanter fremgår av Tabell 5:
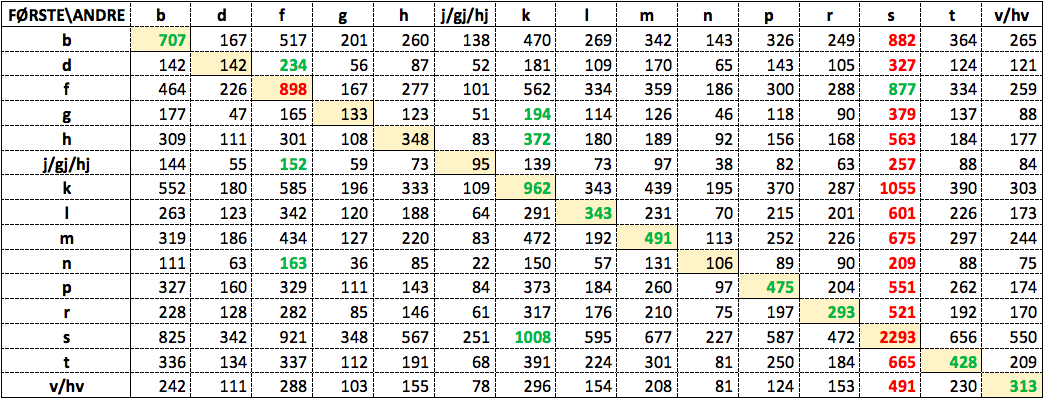
Tabell 5: Typefrekvenser av hver kombinasjon av første og annen initialkonsonant
(Tabellen kan sees i større format her.)
Mønsteret ved unormalisertte frekvenstall avviker ikke sterkt fra det vi så i Tabell 3, der vi telte eksemplarer. Den høyfrekvente s dominerer enda litt mer som den mest frekvente andrekonsonanten, og i den gulmarkerte diagonalen, altså cellene med de allittererende parene, har vi fått én andreplass (grønt tall) mer enn vi hadde i Tabell 3, og like mange førsteplasser (røde tall). Også her er det nødvendig å fjerne virkningen av de svært ulike globale frekvensene av konsonantene ved å normalisere eller vekte frekvenstallene til det de ville ha vært hvis alle konsonanter hadde hatt samme globale frekvens. Utregningsmåten er den samme som den som beskrives over Tabell 4. Gjennomsnittet av kolonnesummene i Tabell 5 er 3 963. Resultatet er Tabell 6:
 Tabell 6: Normaliserte typefrekvenstall basert på antatt lik frekvens mellom konsonantene
Tabell 6: Normaliserte typefrekvenstall basert på antatt lik frekvens mellom konsonantene
(Tabellen kan sees i større format her.)
I Tabell 6, med vektede frekvenstall, ligger alle de 15 maksimale frekvenstallene for andrekonsonanten i den allittererende diagonalen fra b-b til v/hv-v/hv. Det innebærer altså at for hver initial førstekonsonant (når vi eliminerer virkningen av ulike globale konsonantfrekvenser) er valget av den samme initiale konsonanten som andrekonsonant alltid det vanligste. Som vi så i avsnitt 3, der vi så på konsonantene samlet, er valget av allittererende initial 2,3 ganger så vanlig som man skulle vente hvis gjennomsnittet er forventningen; Tabell 6 viser at denne dominansen av allitterasjon faktisk også gjelder for hver enkelt konsonant.
5. Konklusjon
Studien viser en klar tendens til å velge allittererende koordinasjoner av enkle substantiver, med over dobbelt så høy forekomst som man skulle vente ut fra en nullhypotese at allitterasjon ikke spiller noen rolle for ordvalget. Vi ser også at allitterasjonstendensen ikke er begrenset til visse konsonanter, men er spredt over i hvert fall 14 av de 15 aktuelle konsonantene når vi teller teksteksemplarer (da med noen andreplasser i diagonalen), og over alle 15, med bare førsteplasser i diagonalen, når vi teller typer istedenfor eksemplarer, og normaliserer oss bort fra virkningen av konsonantenes ulike globale frekvenser. Også bokstavrim – ikke bare rytme – synes altså å ha røtter i det alminnelige språket.
Dette kan kanskje være en kilde til kunnskap om struktur og mekanismer bak menneskets språkbeherskelse. Jeg tror lingvister ofte undervurderer betydningen av metriske egenskaper i sine teorier om språktilegnelse og språkbruk. Psykologer har vært inne på det, f.eks. Stein Bråten i Norge. Det har vært observert at preverbal kommunikasjon med spedbarn har rytmiske egenskaper, og rytme og intonasjonsmønstre tilegnes tidlig. Elementene i rytmen (i språk som norsk) er de trykksterke stavelsene, og det håndtaket vi bruker når vi griper fatt i et ord og dets trykksterke stavelse og plasserer det inn som et taktslag i talestrømmens rytmepartitur, er nettopp den initiale konsonanten. Vi føler velvære når vi eller andre får det til og det passer, og ekstra velvære når rytmepar har samme håndtak – samme initiale konsonant, eller samme fravær av initial konsonant ved vokalisk allitterasjon. En nærliggende tanke er at den initiale konsonanten er ordets adresse – omtrent som CAR i Lisp, kunne man si med en lett eksentrisk sammenligning. Å løpe gjennom alfabetet på jakt etter riktig initial er en velkjent teknikk når man ikke husker et navn. Når rytmen svikter og håndtaket glipper, kan resultatet bli stamming, som nettopp rammer den initiale konsonanten. Og det er ikke tilfeldig at sang er et velkjent remedium mot stamming; her har musikk og språk en felles kilde.
Stavrim, styrk initialen!
Rakner rytmen, tynes talen.