
Innledning
En trebank med utførlige syntaktiske analyser kan gi grunnlag for et mer nyansert mål på setningers kompleksitet enn f.eks. det mye benyttede lix, som bare tar hensyn til ren setnings- og ordlengde (se Wikipedia om lix/liks). Et slikt mer nyansert mål ville da selvsagt forutsette at de tekstene som skal måles, er analysert syntaktisk, men ved hjelp av en komputasjonell grammatikk som NorGram ville det i prinsippet være mulig å lage en trebank av en tekst tilnærmet automatisk, slik det har skjedd med NorGramBank. I dette innlegget vil jeg se nærmere på noe som kan tenkes som en komponent i et slikt mulig mål, og hvordan det slår ut på tekster fra NorGramBank.
Et mål på syntaktisk kompleksitet
En side ved syntaktisk kompleksitet som lix ikke tar hensyn til, er graden av innføying – altså i hvilken grad setningen har en hierarkisk struktur der fraser er innføyet i fraser som igjen er innføyet i fraser, osv. Her kan vi særlig tenke på en rekursiv struktur, som betyr at de omtalte frasene er av samme art – for eksempel leddsetning innføyet i leddsetning innføyet i leddsetning, osv. (Leddsetninger har alltid et finitt verb – et verb i presens eller preteritum – så vi tar ikke infinitivskonstruksjoner i betraktning her.) Blant de mange alternative målene på kompleksitet vi kunne definere, velger vi å prøve ut dette kriteriet. Vi vil da gi en setning en vekt som både tar hensyn til antallet leddsetninger i den, uavhengig av om de er innføyet i hverandre, og dessuten til dybden i en slik eventuell innføying. Vi vil anta at kompleksitetsvekten øker sterkere enn lineært med antallet «etasjer» i et slikt hierarki: Fire etasjer skal være mer enn dobbelt så tungt som to. Kompleksiteten i en tekst blir da setningenes gjennomsnittlige vekt.
I hvilken grad denne typen kompleksitet faktisk er korrelert med lesbarhet, er et empirisk spørsmål som jeg ikke har undersøkt. Det kan være grunn til å mistenke at det kan bli noe for enkelt å ta denne kompleksiteten alene som et mål på lesbarhet, ettersom måten setninger er innføyet i hverandre på, åpenbart spiller en stor rolle for lesbarheten. En rent høyreforgrenet struktur, der leddsetninger står til slutt i de setningene de er innføyet i og ikke midt i eller nær begynnelsen, behøver ikke å være særlig tunglest i det hele tatt. Men det kan være interessant å utprøve en kombinasjon av slik kompleksitet med andre egenskaper ved setningen; det vil jeg komme tilbake til i senere blogginnlegg.
For å illustrere hvordan vi kan registrere antallet leddsetninger og graden av inføying gjennom søking i trebanken, må vi betrakte noen analyseeksempler. I eksemplene skal vi bruke grønn for leddsetninger på første nivå, blå for leddsetninger på annet nivå (altså innføyet i leddsetning på første nivå), rød for leddsetninger på tredje nivå, lilla for leddsetninger på fjerde nivå, grå for leddsetninger på femte nivå og fiolett for leddsetninger på sjette nivå. I en romantekst finner vi denne setningen:
(1) De så at han kvakk da hornsignalet lød.
(1) inneholder to leddsetninger: (a) at han kvakk da hornsignalet lød og (b) da hornsignalet lød. (a) er innføyet i helsetningen (1), og (b) er innføyet i leddsetningen (a). (Vi ser bort fra den alternative tolkningen der begge leddsetningene står på samme (grønne) nivå og modifiserer helsetningen, altså verbet så.)
Analysen av setning (1) i trebanken vises i figuren nedenfor:
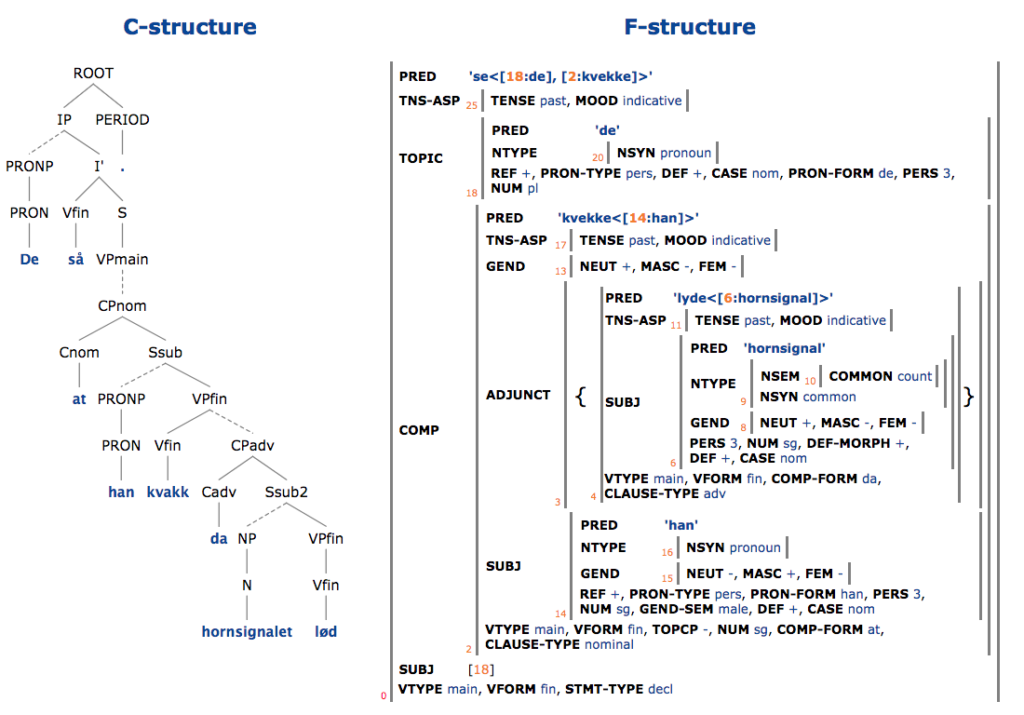
C-strukturen viser setningens oppbygning av fraser og delfraser, f-strukturen viser en analyse i funksjoner og trekk. For vårt formål her skal vi konsentrere oss om c-strukturen:
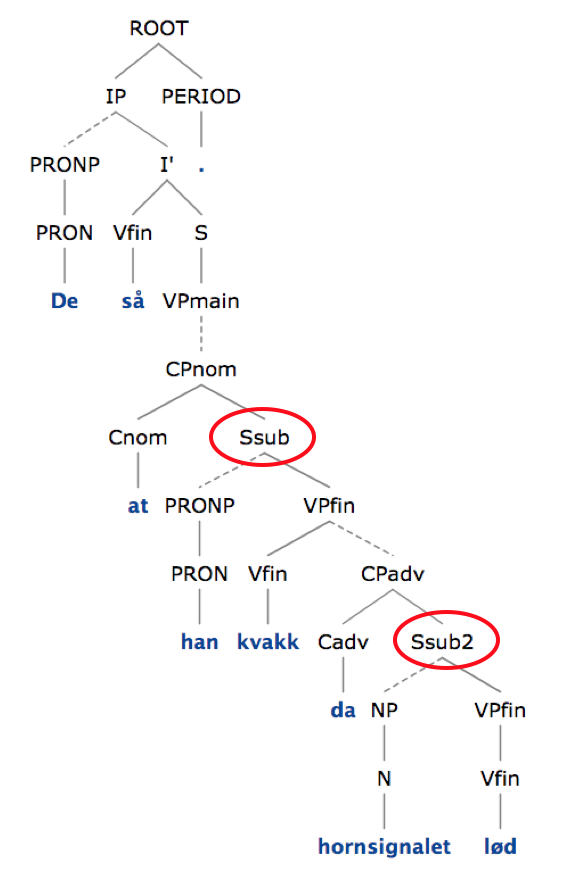
Alle leddsetninger, også de uten subjunksjon (at, da, …), har en node kalt Ssub eller Ssub2. (Forskjellen mellom Ssub og Ssub2 har å gjøre med hvorvidt subjektet er obligatorisk og er ikke relevant her; vi vil referere til begge med Ssub*.) Denne noden kan vi derfor bruke til å telle leddsetninger, og til å registrere hvorvidt en leddsetning er inkludert i en annen. At en leddsetning er inkludert i en annen, fremgår av at en node Ssub* dominerer en annen node Ssub*. I tillegg til å telle leddsetninger, teller vi da også slike dominansforhold i setningen. I setning (1) har vi to noder Ssub* og ett dominansforhold mellom to slike noder, og dermed blir vekten av denne setningen 3.
For å se hvordan dypere hierarkier påvirker vekten, kan vi betrakte en mer kompleks setning fra trebanken:
(2) Metodikk som det kan dokumenteres at bidrar til en positiv utvikling for barna må få større plass i utdanningene, mens studenter i mindre grad trenger å lære om metodikk som en ikke kan dokumentere at virker.
C-strukturen for denne setningen vises nedenfor:
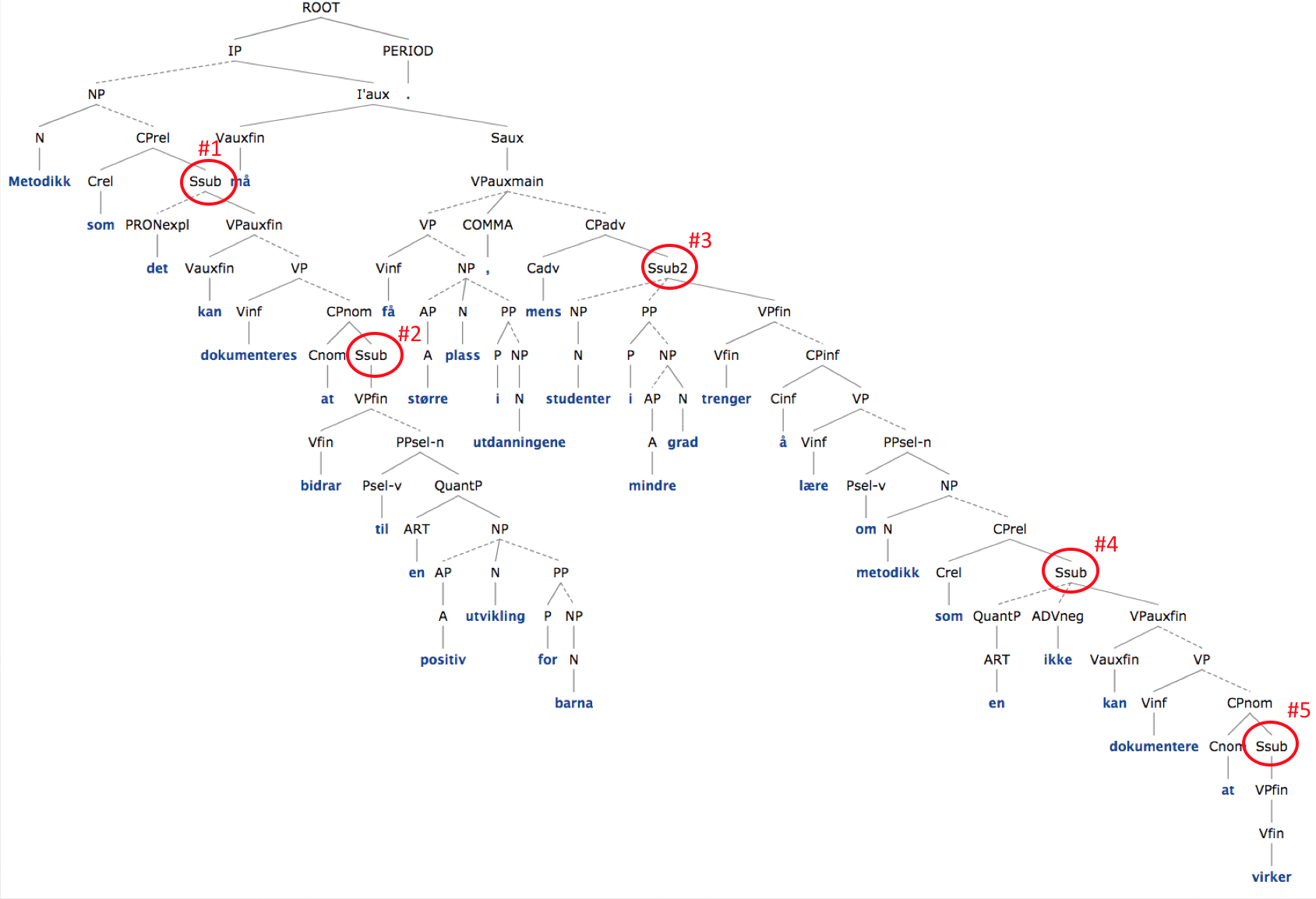
Grafen kan sees i større format her.
Setning (2) inneholder 5 leddsetninger, og c-strukturen har dermed 5 noder Ssub*, markert med rødt i grafen. Dessuten er det 4 dominansrelasjoner mellom Ssub*-noder (vi markerer direkte og indirekte dominans med ‘>*’):
#1 >* #2
#3 >* #4
#3 >* #5
#4 >* #5
Siden dominansforhold som det mellom #3 og #5, med en mellomliggende Ssub*-.node, også teller med, ser vi hvordan antallet dominansforhold øker mer enn lineært med tilføyelsen av nye nivåer i hierarkiet. Hvis D(n) er antallet dominansforhold i et hierarki med n nivåer, blir da forholdet slik:
D(1) = 0
D(n) for n > 1 = D(n – 1) + (n – 1)
Dette innebærer da at et hierarki av leddsetninger med f.eks. 5 nivåer vil få en dominansvekt på 10, som er verdien av D(5). Setning (2) har ett hierarki med 2 nivåer og ett med 3. Vekten for det første hierarkiet, D(2), er da 0 + (2 – 1) = 1, og for det andre, D(3), er vekten 1 + (3 – 1) = 3, til sammen for de to hierarkiene 4. Vekten for setning (2), når vi både teller leddsetninger og dominansforhold, blir dermed 5 + 4 = 9.
Vi kan nå registrere setningenes vekt ved å kombinere to søkeuttrykk. Uttrykket for å registrere dominansforhold er slik:
Ssub* >* Ssub*
Dette søkeuttrykket sier at en node Ssub* direkte eller indirekte dominerer en annen node Ssub*. Uttrykket finner alle setninger der dette er sant. Men i tillegg til å finne setningene, registrerer søkeprosessen også hvor mange treff uttrykket har i en viss setning. I setning (1) vil da uttrykket ha ett treff, og i setning (2) vil det ha 4. Antall treff kan da inngå i utregningen av vekten.
For å telle selve leddsetningene i en setning er det tilstrekkelig å skrive:
Ssub*
Dette søkeuttrykket finner alle setninger med minst én leddsetning, altså alle der minst én node har etiketten Ssub*. I tillegg, som ovenfor, registreres det hvor mange treff uttrykket har i en viss setning, altså antallet leddsetninger i dette tilfellet. Det gir 2 for setning (1) og 5 for setning (2).
Vi kan nå kombinere de to søkeuttrykkene i en enten/eller-forbindelse – en disjunksjon. I søkespråket uttrykkes disjunksjon med ( … | … ), så resultatet blir da:
( Ssub* >* Ssub* | Ssub* )
Dette uttrykket finner alle setninger der ett eller begge de to alternativene er sanne, og det registreres hvor mange treff i en setning vi da til sammen får.
Vi kan illustrere resultatet ved å bruke dette søkeuttrykket på to deltrebanker, nno-child, som er barnebøker på nynorsk, og nor-stortinget_1, som er en del av stortingsforhandlingene. Vi føyer til en referanse til ‘treebank’ for å få resultatene sortert etter trebank:
( Ssub* >* Ssub* | Ssub* ) :: treebank
Resultatet ser da slik ut:

Antall treff i de to trebankene er da summen av antall treff i hver setning, som er vårt mål på setningen kompleksitet. Vi ønsker ikke bare å registrere summen av alle setningenes vekt i en tekst, men også hvordan denne vekten forholder seg til det totale antallet setninger i teksten. Vi trenger derfor å telle de relevante setningene, som er de som har fått komplette analyser i trebanken (noen av setningene i trebanken har såkalte fragmentanalyser, men dem ser vi bort fra her). Alle slike setninger har en toppnode som heter ROOT. Vi kan da bruke søkeuttrykket:
ROOT :: treebank
Med uttrykket ROOT finner vi alle setninger med en node ROOT, det vil si alle fullstendig analyserte setninger i korpus. Resultatet ved søk i de to nevnte deltrebankene gir oss antallet relevante setninger i hver av dem:

For trebanken nor-stortinget_1 ser vi at vektsummen (193700) er større enn antallet setninger (173370), og den gjennomsnittlige vekten pr. setning er 193700 / 173370 = 1,117. For trebanken nno-child, derimot, er vektsummen (33248) mindre enn antallet setninger (90341), og gjennomsnittet pr. setning er 33248 / 90341 = 0,368. For å få måleverdier av samme størrelsesorden som lix ganger vi gjennomsnittene med 100, og får da:
|
Trebank |
Kompleksitet |
| nor-stortinget_1 |
112 |
| nno-child |
37 |
Som ventet kommer stortingsforhandlingene ut med en betydelig større syntaktisk kompleksitet enn barnebøkene. En setning som (3) fra nor-stortinget_1 ligger ikke nær noe man vil vente å finne i en vanlig barnebok.
(3) Føler helseministeren at de situasjonene som har blitt beskrevet fra Ahus, tilfredsstiller det kriteriet som helseministeren da trakk opp, og som Stortinget var enig i, nemlig at det ikke skulle overføres pasienter før det var helt sikkert at pasientene skulle få et minst like godt tjenestetilbud ved Ahus som det de hadde før prosessen startet?
Som nevnt ovenfor er det et empirisk spørsmål i hvilken grad denne typen kompleksitet faktisk er korrelert med lesbarhet. Men denne kompleksiteten kan likevel bidra til å karakterisere stilen hos en viss forfatter eller i en viss teksttype, og vi skal se litt nærmere på den.
Kompleksitet i deltrebankene
NorGramBank består av flere deltrebanker av ulik art og ulik størrelse, se oversikten her.
Hvis vi regner ut kompleksiteten etter våre leddsetningskriterier for hver av disse deltrebankene og rangerer dem fra mest til minst kompleks, får vi denne tabellen:
Deltrebanker rangert etter syntaktisk kompleksitet:
| Deltrebank | Kompleksitet |
| nor-stortinget_2 | 113 |
| nor-stortinget_1 | 112 |
| nor-stortinget_3 | 110 |
| nor-stortinget | 107 |
| nor-stortinget_4 | 97 |
| nob-sofie | 86 |
| nob-fn | 82 |
| nob-lbk-sa | 67 |
| nob-ndt-lfg | 60 |
| nob-avis | 59 |
| nno-nnk-av | 58 |
| nno-nnk-sa | 55 |
| nob-lbk-av | 55 |
| nob-novel_2 | 48 |
| nob-novel_4 | 47 |
| nob-novel_3 | 46 |
| nob-novel | 46 |
| nob-novel_5 | 44 |
| nob-novel_1 | 44 |
| nob-child | 42 |
| nno-novel | 41 |
| nno-child | 37 |
| nob-lbk-tv | 26 |
Rangeringen sorterer tydelig mellom de ulike teksttypene. På topp i kompleksitet kommer stortingsforhandlingene samlet. Så kommer Gaarders Sofies verden umiddelbart etter, og før sakprosa, avistekst og andre romaner. Med sitt filosofiske tema skiller den seg tydeligvis ut også syntaktisk. Etter Sofies verden kommer Forskningsnytt og annen sakprosa på bokmål, og så tre deltrebanker med avistekst med én med nynorsk sakprosa innimellom. Deretter har vi alle bokmålsromanbankene samlet, og så barnebøker på bokmål. Romaner på nynorsk kommer etter barnebøker på bokmål i syntaktisk kompleksitet, og til slutt barnebøker på nynorsk og TV-teksting. Vi ser en svak tendens til mer kompleksitet i bokmålstekster enn i nynorsktekster av samme type, men det kan være grunn til å tvile på at den er signifikant. I stortings-trebankene er det ikke skilt mellom bokmåls-og nynorskdelene.
Setningslengde varierer på lignende måte mellom trebankene, med kortere setninger nedover i hierarkiet ovenfor, og man kunne reise spørsmålet om i hvilken grad dette kompleksitetsmålet er en funksjon av setningslengde snarere enn en uavhengig egenskap. Det er åpenbart en sammenheng mellom dem (det er grenser for hvor mange selv korte leddsetninger man får plass til i en setning på 6 ord), men det er likevel ikke tale om en funksjon fra det ene til det andre – de to målene varierer også noe uavhengig av hverandre. Det kan best illustreres når vi betrakter kompleksiteten hos den enkelte forfatter.
Kompleksitet hos forfatterne
Det er også mulig å studere kompleksiteten i tekstene hos den enkelte forfatter ved de tekstene der forfatteropplysninger foreligger. Det er ikke tilfellet i stortingsforhandlingene, men forfattere er oppgitt for romanene, barnebøkene, sakprosaen og deler av avistekstene. Det totale antallet forfattere og grupper av forfattere (ved felles forfatterskap) i materialet er 2658, representert med tekster av svært varierende lengde. Hvis vi ser bort fra forfattere som er representert med færre enn 10 setninger, varierer kompleksitetsmålet fra 260 til 4.
I utregningen av setningslengde telles både ord og skilletegn. Vi kan betrakte samvariasjonen mellom kompleksitet og setningslengde ved å plotte forfatterne inn i et diagram med kompleksitetsmålet langs x-aksen og gjennomsnittlig setningslengde langs y-aksen.
Kompleksitet og setningslengde hos 2658 forfattere:
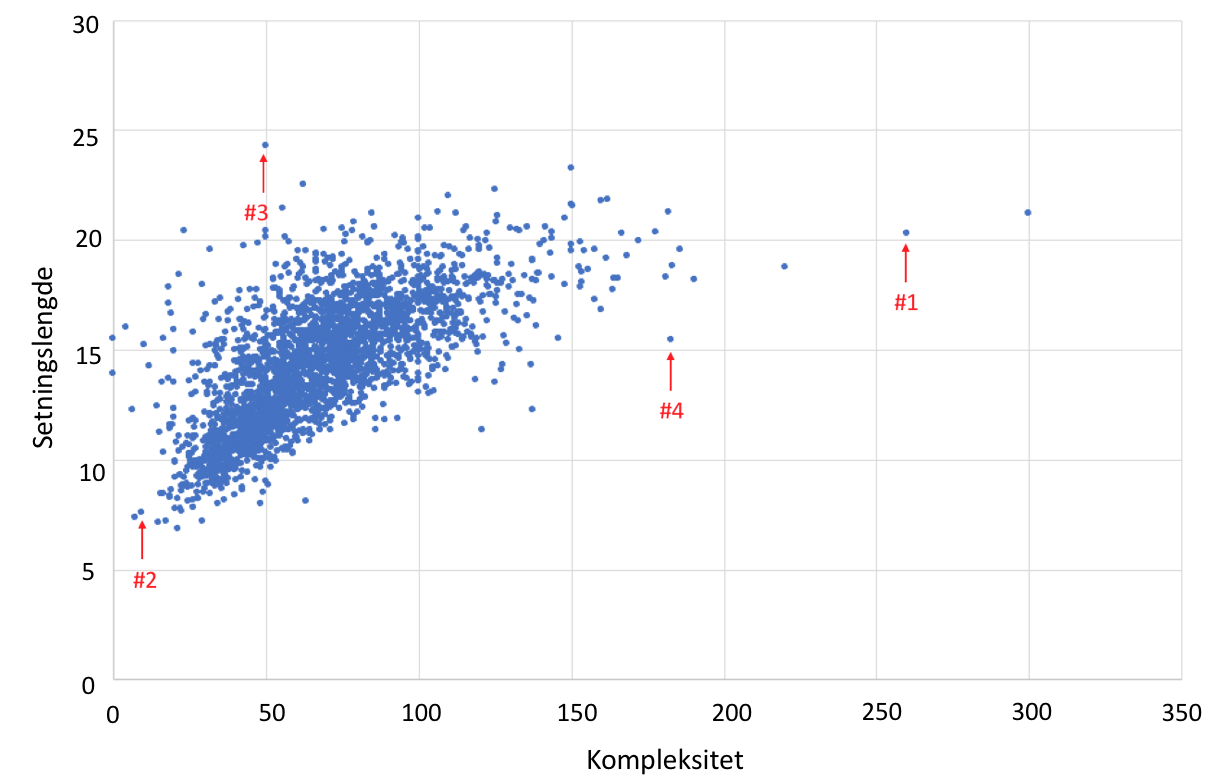
Tendensen til spredning langs en avlang sky fra nederst til venstre (lav kompleksitet, korte setninger) til øverst til høyre (høy kompleksitet, lange setninger) viser en viss samvariasjon, men det er også en del avvik fra denne linjen. Vi skal se på tekstutdrag fra de fire forfatterne som er markert med #1 – #4 i diagrammet.
#1 har verdiene 260,20 og skiller seg ut med relativt høye verdier i begge dimensjoner: høy kompleksitet og lange setninger. Tekstutdrag:
Celler spiser kreften
Dette funnet kan bane veien for nye behandlingsformer mot kreft.
– Vi fant at selvspisingsmaskineriet, som vanligvis finnes i alle normale celler, var aktivt og bidro til å bryte ned PML-RARA i blodkreftcellene.
Akutt promyelocytisk leukemi var for bare noen få tiår siden en svært dødelig sykdom uten noe effektivt botemiddel.
– Dette er definitivt en av de største suksesshistoriene noensinne når det gjelder forskning som har ledet til effektiv kreftbehandling, uttaler Bøe.
Han forklarer videre at det er svært sjeldent at man treffer så bra med en målrettet kreftbehandling, og at han tror man ikke helt har forstått hvorfor denne terapien er så effektiv som den er.
Derfor har han lenge vært overbevist om at det her må finnes noen generelle prinsipper vi kan lære av og som kan være overførbare til behandling av andre krefttyper.
I tillegg forekommer det at pasienter med akutt promyelocytisk leukemi ikke blir fullstendig kurert av dagens behandling.
Proteinet PML-RARA holder blodkreftcellene i en umoden tilstand ved å hemme uttrykket av mange gener som er kritiske for deres normale utvikling.
Ved behandling med retinsyre blir mange av disse genene aktivert igjen.
Setningene er informasjonsrike, men tekstutdraget illustrerer også at denne typen kompleksitet ikke har noen klart negativ virkning på lesbarheten. Det er en klar og presis fremstilling.
#2, en barneboktekst, er i motsatt ende av begge skalaer med verdiene 9,8: lav kompleksitet, korte setninger. Her er et utdrag:
Bø og Bæ i festhumør
Bø og Bæ pyntar seg.
Dei skal på fest hos Bo.
Det skal vere dans.
Bø må øve.
Kva heiter dansen?
Bø blir ør.
Han må kvile seg ei stund.
Bø og Bæ skal ha med ei gåve til festen.
Bo skal få ein båt.
Det er moro å pakke inn, synest Bø og Bæ.
Og lett når ein er to.
«Merkeleg,» seier Bø.
«Korleis gjekk dette til?»
Ein kartong er betre, synest Bæ.
Stødigare også, synest Bø.
Hyssing er finare enn teip.
Bo bur like ved.
Her bur Bo.
«Gratulerer, Bo!» seier Bø og Bæ.
Bo blir glad.
Bø og Bæ får kvar sin hatt.
Alle er der.
Bø og Bæ er svoltne.
Etterpå blir det dans.
Bø dansar godt!
#3, med verdiene 50, 24, har lav kompleksitet og høy setningslengde og illustrerer at de to verdiene i noen grad kan variere uavhengig av hverandre:
Er fiskefôret sunt?
Jeg forsker på bruk av genmodifiserte planteråvarer i fiskefôr, hovedsakelig til laks.
Dette er en svært relevant problemstilling for NIFES sin rolle som kunnskapsleverandør til forvaltningen i Norge.
Bruk av planteråvarer i fiskefôr som erstatning for fiskemel og fiskeolje er en nødvendighet både for å få til en mer bærekraftig produksjon og en videre vekst i produksjonen.
Flere av de aktuelle planteråvarene, som for eksempel soya, mais og raps, blir i stor grad dyrket som genmodifiserte (GM) varianter.
Dermed er det viktig å fremskaffe kunnskap om GM råvarene trygt kan benyttes i fôret uten noen effekt på fiskens vekst eller helse.
Kunnskap om mulige effekter av GM råvarer er svært viktig både for forvaltningen og næringa, slik at de kan ta sine avgjørelser basert på vitenskapelige data.
Fisken ble fôret gjennom 7 måneder, inkludert sensitive stadier i livssyklus som smoltifisering og utsett i sjø, og omfattende evalueringer ble gjort av fiskens vekst, utvikling og helse gjennom hele forsøket.
Jeg er oppvokst på kysten (Hvalerøyene i Østfold) med en far som er rekefisker, så det kan nok ha hatt innvirkning på interesser og utdanningsvalg (master i havbruksbiologi).
Da jeg skulle gå videre på doktorgrad, valgte jeg å spesialisere meg innen ernæring da dette gir varierte jobbmuligheter seinere, både for forskning i det offentlige og i privat industri.
Her er den gjennomsnittlige setningslengden (i hele teksten) høyere enn hos #1, men innslaget av leddsetninger er betydelig mindre, og vi ser ingen eksempler på leddsetning inne i leddsetning i utdraget.
#4 med verdiene 183,15 er blant dem som kommer nærmest den siste mulige kombinasjonen – høy kompleksitet kombinert med lav setningslengde – eller i dette tilfellet middels setningslengde. Riktignok skyldes nok den lave gjennomsnittlige setningslengden i stor grad innslaget av korte overskrifter. Her er et utdrag:
Klisterforbud skaper trøbbel for Byåsen
Det skjer etter at Spektrum har tatt inn kommunens regler i hallen.
Klisteret brukes av spillerne for å få bedre tak på ballen, men setter samtidig merker på gulvet.
Sprayklister setter ikke like markante merker, men har kortere varighet.
– J12 – kamper
– Dette blir jo som å spille J12-kamper igjen, sier daglig leder i Byåsen, Torbjørn Balstad.
Argumentet til kommunen er at harpiksen som er i klisteret gjør at det blir merker på gulvet som er vanskelige å vaske vekk.
Men Balstad hevder at produsenten av klisteret de bruker nå, kan dokumentere at det ikke er harpiks i det.
– Hva skjer når det kommer motstandere hit som skal spille kamp mot oss?
Skal lag som Lubin og Larvik bruke sprayklister?
Tvilsomt, tror Balstad.
Klister av den gamle typen, som inneholder harpiks, brukes kun ved meget varme forhold i hallen, der vanlig klister kan bli for glatt.
– Det blir som å si at gutta på Lerkendal skal spille med fastknotter fordi skruknotter ødelegger gresset, sukker Balstad oppgitt.
Sier ikke kategorisk nei
Teknisk sjef i Trondheim Spektrum, Håkon Sjøhaug, avviser ikke at vanlig krukkeklister kan brukes, dersom det kan dokumenteres at det ikke inneholder harpiks.
Men vi har en god dialog med Balstad, som har gjort oss oppmerksomme på at det finnes krukkeklister uten harpiks, sier Sjøhaug.
Må ha databladet
– Ser du for deg at den kan vekke reaksjoner dersom storlag som Buducnost og Larvik kan bli nødt til å bruke sprayklister når de kommer hit for å spille kamp?
– Hehe, ja.
Og dersom vi har andre regler enn for eksempel i Larvik, så er dette uheldig.
Jeg mener vi bør få likt reglement på alle hallene i Norge.
– Dersom det ikke er harpiks i klisteret, er vi åpne for å se på om det kan brukes.
Når vi får databladet fortsetter vi dialogen med Byåsen, sier Sjøhaug.
Konklusjon
I dette innlegget har jeg sett på hvordan informasjon om en type syntaktisk kompleksitet kan hentes ut av trebanken og brukes til å karakterisere ulike teksttyper og ulike skribenter. Det gjenstår å se om akkurat denne typen kompleksitet er informativ om tekstegenskaper som er relevante for lesbarheten, men det kan være av interesse å kombinere dette kompleksitetsmålet med mål basert på andre tekstegenskaper som lar seg hente ut. Det vil jeg se på i senere innlegg.
Én kommentar til “Setningskompleksitet: et mål på lesbarhet?”